Welcome back for the second part of Parallelism Week here at SQL University. Get your pencils ready, and make sure to raise your hand if you have a question.
Last time we covered the necessary background material to help you understand how the SQL Server Operating System schedules its many active threads, and the differences between its behavior and that of the Windows operating system’s scheduler. We also discussed some of the variations on the theme of parallel processing.
Today we’ll take a look at the various elements you can expect to see in parallel query plans. After reading this post you will have a solid foundation for interpreting the parallel aspects of your plans, and you will be able to investigate what the query processor is actually doing as your query is evaluated. So without further ado I present…
A Primer on Parallel Query Plans
As mentioned in the prior post in this series, the query optimizer makes the initial “go” or “no-go” decision when it comes to parallelism. This is done by taking a number of factors into consideration in trying to determine whether it’s worth the effort to process the query in parallel. But more on that in the next post; for now suspend your disbelief and assume that a parallel plan already has been generated. Like this one:

A lot of things are going on in this plan, and we’ll take it step by step. If you’d like to take a look at the plan on your end, check out the .SQLPLAN file attached to this post.
First of all, how do we know that this is a parallel plan? Aside from looking at the showplan XML, the answer is simple: the little yellow icon. Each iterator in the plan that may be processed in parallel has a circular icon with two arrows, superimposed over its bottom right corner. Notice that not every iterator in this plan is graced by the presence of the magic icon. We may refer to a given plan as “parallel” or not, but in actuality parallelism happens on a per-iterator basis. Some iterators can be processed in parallel, and others can’t. Furthermore, the optimizer may decide that a certain subtree of a plan should be processed in serial rather than in parallel. So it’s quite common to see a combination of serial and parallel iterators in your plans.
In addition to the fact that not all iterators can be processed in parallel, most are not actually parallel-aware. In truth, the only two operations able to inherently deal with parallelism are index scans and exchange operations. Note that in this context “index scans” refers to both full scans–as shown in the plan above–and range scans labeled as “Index Seek.” Exchange operators–the primary components that control the flow of parallel data in the query processor–are labeled as “Parallelism” in the graphical showplan representation. They come in three flavors:
- Gather Streams iterators accept multiple input sets of rows on a number of threads and output a single set of rows on a single thread. These iterators can be either merging or non-merging. The merging version takes multiple sets of sorted rows and merges them to output a single set of rows in the same sorted order.
- Distribute Streams iterators accept a single input set of rows and breaks the set into multiple sets of rows on multiple threads, based on one of a number of distribution schemes.
- Repartition Streams iterators are responsible for reading in multiple sets of rows and re-distributing them on different threads using a different distribution scheme than whatever was used for the input threads.
Data is distributed between threads of a parallel plan either by page or by row. As mentioned above, a number of schemes are available. The most common of these are:
- Hash partitioning distributes rows based on a hash value calculated on a set of columns from the input stream. Based on the value, the row is sent to a specific output thread.
- Round-robin partitioning distributes rows relatively evenly across threads by sending the next available row to the next thread in the list, then moving to the next thread, and so on, before moving back to the first thread once every thread has received a row. This pattern is continued until there are no remaining rows to distribute.
- Broadcast partitioning distributes all input pages to every output thread.
To see which scheme is being used by an iterator in a plan you’re working with, investigate the showplan XML (right-click on the graphical showplan and click “Show Execution Plan XML”). Within the XML, search for Parallelism nodes and look at the PartitioningType attribute to see which distribution scheme is being used. And when applicable, refer to the set of ColumnReference nodes under the PartitionColumns subtree to see the columns that are being used in a row-based distribution scheme.
Table scan operations use a demand partitioning scheme whereby threads are spun up and begin requesting pages from the scan iterator. After each thread finishes its downstream work with the rows in the previous page it received, it requests another page, until the iterator has no more pages left to distribute. This scheme helps to eliminate imbalance problems where one thread ends up with a lot more work to do than another due to data skew or other issues.
To gain more insight into how parallel plans work, I will walk you through the plan above, starting with the iterators at the top right. To begin, we’ll tackle the following piece, which is generated from a derived table that selects the top 1000 rows from SalesOrderDetail, ordered descending by SalesOrderDetailId:

- The index scan iterator internally creates a number of threads, determined by a combination of the MAXDOP (maximum degree of parallelism) for the plan and a runtime decision by the query processor (more on this in the next post). Pages are read from the SalesOrderDetail table and are distributed to each of the threads using the demand scheme. On my dual-core notebook two threads are used, one of which receives approximately 55,000 rows, and the other approximately 65,000.
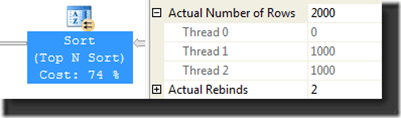
- The Top N Sort iterator, as mentioned before, is not parallel-aware, so the data on each of the two threads is sorted independently of the other. Because some or all of the top 1000 rows could be in either of the two streams, 1000 rows are returned by each, for a total of 2000 rows output by the iterator.
- In order to find the top 1000 rows, the two streams must be merged into one. The Gather Streams exchange iterator takes care of this, reducing the two input streams to one for input into the serial Top iterator.
- The Top iterator finds the top 1000 rows and outputs them to the next iterator downstream.
Information on the actual number of rows processed by each thread is available in the graphical showplan viewer. Select the iterator you’re interested in and press F4 on your keyboard. Expand Actual Number of Rows and you’ll see output like the following:
Next we’ll cover the segment of the plan downstream from the Top iterator:

- Due to the fact that the Top iterator was processed serially, its output is a single stream on a single thread. In order to continue processing the data in parallel, the stream is distributed into two sets of rows using the Distribute Streams exchange iterator. The sets are determined based on a hash of the SalesOrderId column.
- A bitmap is created for each set of rows, and each set feeds into a hash build. This means that in actuality two hash tables are built–one for each thread.
Keep that hash table in mind and consider the lower subtree:

- First the SalesOrderHeader table is scanned. Just like the scan of SalesOrderDetail discussed above, this one is parallel-aware, and the pages are also partitioned using the demand scheme.
- Recall that the data in the previous segment we evaluated is partitioned based on a hash of SalesOrderId. Two hash tables have been built, each of which corresponds to a unique set of the IDs. In order to effect the join between the two tables, the rows from this lower segment of the plan will be used to probe the hash tables to find matching rows. Before this can happen, the rows must be sent through a Repartition Streams exchange iterator, such that streams can be created that align with the sets of data in the hash tables. So in this particular case, a hash distribution scheme is used and the rows are distributed based on a hash of SalesOrderId. Once this has been taken care of the hash match operations on either thread can be done independently of the operations on the other thread.
So What Did We Just See?
If you get nothing else out of this blog post, I hope that you’ll remember the following bits:
- A “parallel plan” will include one or more parts that can be processed in parallel, but these can be interspersed with other parts that are processed serially. The plan can, essentially, go in and out of a parallel state.
- Only a couple of types of operators are actually parallel-aware, and they know how to work with the threads in some way. The rest of the iterators can be run on multiple threads, but neither know nor care that parallelism is being used.
- A lot of information on parallelism is hidden both in the SSMS graphical showplan and the showplan XML itself. Getting comfortable with the F4 button–for more information on selected graphical showplan nodes–and a good editor for reading the underlying XML are both key to query plan mastery.
Next Time
This marks the end of the second post in my three-part SQL University series on parallelism. The final post will deal with options and settings that impact parallelism, and we’ll also take a brief look at some of the parallelism metadata available via DMVs. Your homework is to look at parallel plans on your servers and let me know what questions you have. As usual, I’ll monitor the comments below and answer as soon as I can.
Until we meet again, thanks for reading and enjoy!
File Attachment: machanic_parallelism_sqlu.zip

Great stuff Adam, thanks for sharing this.
Enjoying the series. Learning a lot about how parallelism works.
Hey Adam,
Three things:
1. It’s possible to read your description of repartitioning as saying that some schemes pass rows around, while others pass pages. The producer threads within an exchange iterator always push ‘packets’ of rows to consumer threads, regardless of the partitioning type (broadcast, round-robin, demand, hash).
2. Parallel scan does not use broadcast partitioning. It starts by threads requesting a row range or page set from a parallel page supplier in the storage engine. Once a thread finishes its initial work, it requests another set. This means that different threads can process a different number of rows (as you saw), which would not be possible if a strict round-robin scheme were used. Parallel scan uses this demand-based scheme to improve plan resilience in the face of data skew and/or scheduler load imbalances.
3. To be fair to parallel hash join, I would have mentioned that a hash partitioning distribution scheme results in a number (DOP) of hash tables which overall use the same amount of memory regardless of DOP. The other possibility for parallel hash join (broadcast) results in a memory grant requirement which is proportional to DOP.
Paul
Hi Paul,
Thanks for the feedback. I’ll go back through later and clarify some of the text based on your comments (1) and (2), in addition to a quick re-read of some of Craig Freedman’s material (should have done that BEFORE writing this stuff).
As for your comment (3), workspace memory grants are an additional complexity wrinkle (and quite a complex one at that) and I think would simply confuse things at this point in the series.
Cheers Adam,
I see what you mean about point 3, but people get so down on parallelism already…I felt sorry for it I guess 🙂
Paul
Very nice stuff Adam!
Thanks for the awesome info Adam & Paul! 🙂
What an awesome series Adam. Thanks.
Hi Adam,
Thanks for the awesome stuff, the exchange operator Distribute Streams seems to be ruining the estimates of one of my query plans. Is it intended to do so? It is accepting 14 rows and returning 56 rows. Estimated row count is 14 and actual is 56.
Hash match operation followed by this is estimated incorrectly whereas the Actual rowcount is twice as the estimated rowcount.
Thank you.
@Sadheera
I don’t think the goal is ever to ruin estimates 🙂
In this case, based on 56/14 = 4.0 I’m guessing your partitioning scheme is Broadcast and your DOP is 4? If that’s the case then the estimates are dead on. Am I correct?
A 2x actual count is actually not that big a deal. I would usually not be especially concerned until it hits something more like 10x. Is there a different plan shape that you think would be ideal and that might fit given better estimates?
–Adam
Comments are closed.