“Even experts with decades of SQL Server experience and detailed internal knowledge will want to be careful with this trace flag. I cannot recommend you use it directly in production unless advised by Microsoft, but you might like to use it on a test system as an extreme last resort, perhaps to generate a plan guide or USE PLAN hint for use in production (after careful review).”
So wrote Paul White in his often referenced article, “Forcing a Parallel Query Execution Plan.” His article focuses on the various reasons that you might not get a parallel query plan, chief among them the optimizer simply not doing a great job with its own cost model. (My session from the 2012 PASS conference, available on YouTube, also discusses the issue in some detail, and from a different perspective. You might want to both watch it and read Paul’s article, prior to reading any further here.)
The trace flag Paul mentions, 8649, is incredibly useful. It allows us to tell the query optimizer to disregard its cost-based comparison of potential serial and parallel versions of our plans, thereby skipping right to the good stuff: a parallel plan (when it’s possible to generate one). Alas, the flag is undocumented, unknown, and its full impact difficult to understand. And for those cowboys who are willing to take the plunge and use it in a production environment, there are still other issues lying in wait:
- This flag is not something you want to enable on a system-wide basis. You can use DBCC TRACEON on a case-by-case basis, but as Paul shows in his post it’s much nicer to use the QUERYTRACEON hint. Unfortunately, this hint was, just like the flag, entirely undocumented until only recently. It is now documented only for a very small number of flags; 8649 isn’t one of them.
- Just like DBCC TRACEON, QUERYTRACEON requires significant system-level privileges: system administrator, to be exact. This means that you’re forced to either give that permission to all of your users, or do some module signing. Clearly the latter approach is far superior, but it’s still a pain.
- QUERYTRACEON, being a query-level hint, can’t be encapsulated in a view or inline table-valued function. So if we want to force these to go parallel, we’re pretty much out of luck.
Clearly, while invaluable for testing, 8649 just isn’t the parallel panacea we need.
Before we get into the details of the solution I’ll be presenting here, it’s probably a good idea to do a quick review of the situation.
Here’s the problem, in brief:
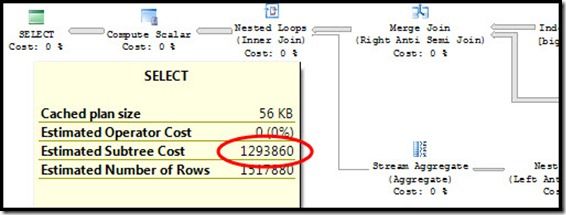
Big plan, no parallelism. Ouch. Or maybe I should say that more slowly. OOOOOOOOuuuuuuuucccccccchhhhhhhh. Because you’re going to be waiting for quite a while for this plan to finish.
Why did this happen? We can find out by forcing a parallel version of the plan using 8649 and evaluating the metadata.
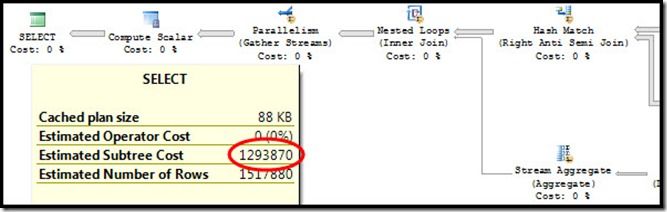
When the query optimizer decides whether or not to select a parallel plan, it first comes up with a serial plan cost, then compares it to the parallel plan cost. If the parallel plan cost is lower, that’s the one that gets used. This parallel plan cost is based on the serial cost, but with a few key modifications:
- CPU costs for each iterator are divided by the degree of parallelism…except when they sit beneath a parallel nested loop. (Except when the input to the parallel nested loop is guaranteed to be one row. That’s a very special parallelism edge case.) Notice the nested loop iterator above? Strike one. (Note: I/O costs aren’t divided by anything.)
- Sometimes, the parallel plan will have slightly different iterators than the serial version, due to the optimizer doing its job. Notice, above, that the iterator feeding the nested loop has transitioned from a Merge Join to a Hash Match? That’s going to change the cost. In this case, it’s more expensive. Strike two.
- Parallel iterators are added into the plan as necessary. See that Gather Streams? It’s not free. Strike three.
Adding all of these modifications together, our parallel plan has a higher cost than our serial plan. Cost is the query optimizer’s way of weighing the relative merits of one plan against another, and just like you might choose the less expensive option at a store, so has the query optimizer. A plan with a cost 10 less than some other plan must perform better, right? Well…no. Not in the real world, and especially not when we’re dealing with plans that have estimated costs in the millions.
Unfortunately, as I mention in the video linked above, the costing model is rather broken. And the workaround I suggest in the video–using a TOP with a variable in conjunction with OPTIMIZE FOR–can work, but it has some problems. The biggest issue, as far as I’m concerned? It requires use of a local variable. Which, just like 8649, means that it can’t be used in a view or inline TVF.
So what’s a SQL developer to do?
Recently it hit me. If I could only create a query fragment that had certain properties, I could apply it as needed, just like 8649. Here’s what I set out to create:
- High CPU cost, low I/O cost. This is key. The query fragment had to be able to benefit from the query optimizer’s math.
- No variables. See above.
- A single, self-contained unit. No tables or other outside objects. As much as possible, avoidance of future maintenance issues seemed like a good approach.
- No impact on estimates in the core parts of the plan. This query fragment had to impact plan selection purely on the basis of cost, and without causing the optimizer to make strange choices about join types, execution order, and so on.
After quite a bit of trial and error I arrived at my solution, which I encapsulated into the following table-valued function:
CREATE FUNCTION dbo.make_parallel()
RETURNS TABLE AS
RETURN
(
WITH
a(x) AS
(
SELECT
a0.*
FROM
(
VALUES
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1),
(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1)
) AS a0(x)
),
b(x) AS
(
SELECT TOP(9223372036854775807)
1
FROM
a AS a1,
a AS a2,
a AS a3,
a AS a4
WHERE
a1.x % 2 = 0
)
SELECT
SUM(b1.x) AS x
FROM
b AS b1
HAVING
SUM(b1.x) IS NULL
)
GO
What this does: The function starts with a set of 1024 rows, defined in the row value constructor in CTE [a]. This set of rows is cross-joined to itself four times. The resultant Cartesian set contains 1,099,511,627,776 rows, all of which are forced to pass through a Top iterator as well as a Stream Aggregate. This is, naturally, a hugely expensive operation that generates a very high estimated cost.
Except that in reality there are only 1024 rows. Notice the predicate in CTE [b]: (a1.x % 2 = 0). If you’ve studied a bit of math you know that 1 divided by 2 has a remainder of 1, not 0. But luckily for us, the query optimizer has no way of evaluating that at compile time. It instead asks its sibling, the query processor, to do that work. The plan involves scanning each of the four cross joined sets for a match, but of course no match is ever found. And since cross joining an empty set to any other set results in an empty set, the query processor has no need to scan any but the first set of rows it encounters. So at run time 1024 rows are touched, and that’s that.
Here’s the catch (and it’s a good one, for us): Since the query optimizer doesn’t know that our predicate will never return true, it also doesn’t know how many rows will actually be touched. And it’s forced to assume the worst, that the full cross product will be processed. Therefore, this function delivers a rather large cost estimate of just under 1,000,000. (Serial cost; parallel will be less, due to the aforementioned math.) This number, as a cost goal, is somewhat arbitrary. I originally came up with a function that delivered a cost in the billions, but it added a lot of complexity to the query plans I was working with. So I scaled it back a bit. 1,000,000 should be fine in just about every case. The example above is fairly typical; I usually see these cost problems crop up with very small relative differentials between the serial and parallel plan cost. The really important thing is that 100% of the estimated cost from this function is CPU time. That means that we can take full advantage of the way the optimizer works.
Of course, almost none of the cost is real. This UDF will add a couple of dozen milliseconds to your plan. It will also add around 100ms to the compile time. In my opinion, that doesn’t matter. If you’re playing in the big parallel workload arena you’re not doing thousands of batch requests a second. You’re trying to get your two hour query down to a reasonable amount of time. No one is going to care about a dozen milliseconds.
This function is also engineered so that the output number of rows is guaranteed to be no greater than one. See that SUM, with no GROUP BY? The query optimizer knows that that can’t return more than one row. And that’s a good thing. It gives us that parallelism edge case I mentioned above. (Nested loop with an input guaranteed to be exactly one row.) Another thing? No rows will ever actually be aggregated in that SUM. Its result will always be NULL. But the query optimizer has no way of knowing that, and it comes up with a plan where the entire backing tree needs to be evaluated. That’s why the HAVING clause is there.
Using this function is quite simple. You take your query, wrap it in a derived table expression, and CROSS APPLY into it. No correlation required. Let’s pretend that the query we want to force parallel looks something like this:
SELECT
a.Col1,
b.Col2
FROM TableA AS a
INNER JOIN TableB AS b ON
a.PK = b.PK
Using the make_parallel function to force this to go parallel is as simple as:
SELECT
x.*
FROM dbo.make_parallel() AS mp
CROSS APPLY
(
SELECT
a.Col1,
b.Col2
FROM TableA AS a
INNER JOIN TableB AS b ON
a.PK = b.PK
) AS x
The reason we CROSS APPLY from the function into the query is to keep the high cost on the outer side of any parallel nested loops. This way, the query optimizer’s parallelism math will work it’s magic the right way, yielding the parallel plan we’re after. CROSS APPLY in this case—uncorrelated—can only be optimized as a nested loop itself, and that loop only makes sense if there is at least one row feeding it. Therefore, this query is logically forced to process the TVF first, followed by the inside of table expression [x].
Note that just as with trace flag 8649, there are a number of parallel inhibitors that are still going to keep this from working. And note that unlike when using the trace flag, the base cost of just under 1,000,000 means that even if you have predicates in certain cases that make a parallel plan less than ideal, you’re still going to get a parallel plan. Using this function is effectively applying a big huge hammer to a problematic nail. Use it with caution, make sure it’s appropriate, and don’t bash your thumb.
So what does a query plan look like, once this has been applied? Here’s the same query from the screen shots above, with the function in play:

Hopefully (without squinting too much) you can see the key attributes: There is a new subtree on top of the original query. That’s thanks to the TVF. This subtree is evaluated, and feeds the top Distribute Streams iterator, which then feeds the Nested Loops iterator. Since the input to that Distribute Streams is guaranteed to be one row, it uses Broadcast partitioning. But there is no correlation here, so there is really nothing to broadcast; the net effect of this action is to prepare a set of threads to do the work of processing your query in parallel.
Under the Nested Loops? The same exact plan shape that was produced when I used the trace flag. Same estimates, same iterators, and so on and so forth. The UDF necessarily impacts the plan as a whole, but it works as intended and does not impact any of the parts of the plan we actually care about — the parts we need to make faster in order to get data to our end users.
I’m really excited about this technique. It means that I can play fewer games, worry less about privileges and the potentially negative impact of using undocumented hints, and concentrate more on the data I need the query to return than the physical manner in which it’s being processed.
Bear in mind that there are myriad other problems with SQL Server’s parallel processing capabilities. This technique merely solves one of them, and in all honesty it’s neither the cleanest nor best solution that I can imagine. It’s a start. My hope is that these issues will eventually be addressed by the query optimizer and query processor teams. In the meantime, we as end-users have no choice but to continue to push the product in an effort to get the best possible performance, today, for the queries that we need to run today. Tomorrow, perhaps, will hold a better story.
Disclaimer: This technique works for me. It may not work for you. It may cause some problem that I haven’t yet considered. It may cause your server to literally explode, sending fragments of plastic and metal all over your data center. The function and technique are provided as-is, with no guarantees or warranties, and I take no responsibility for what you do with them. That said, if you DO try this out I’d love to hear about your experience, in the comments section below!
Enjoy!
Special thanks to Gokhan Varol for helping me test this technique.

Creative, educational … and kind of hilarious. Sometimes your blogs make me wish I DIDN’T live in the thousands-of-batch-requests-per-second world. 🙂
Hi Adam,
Regarding the reason for the HAVING clause. It is needed to introduce doubt as to whether the function will produce one row or none at all. Without it, the optimizer can indeed see that exactly one row will always be produced by the scalar aggregate.
The ‘uncorrelated CROSS APPLY’ is in reality a CROSS JOIN. If the optimizer can see that one input to that cross join always produces one row (and no columns are projected from the function) it can remove the entire subtree as redundant, leaving you with just the original statement. The HAVING clause adds just enough obfuscation (in currently released versions) to remove that one-row guarantee.
Comment out the HAVING clause and run:
SELECT CA.* FROM dbo.make_parallel() AS MP
CROSS APPLY
(
SELECT * FROM Production.Product
WHERE Name LIKE N’A%’
) AS CA;
The result is a simple scan of the Product table.
There are some fun features to the idea in this post, but aside from not needing sysadmin permission (for the trace flag) it seems to me to rely on just as many undocumented and unsupported behaviours as any other available solution.
What we really need is proper SQL Server support for parallelism, including an effective query hint.
https://connect.microsoft.com/SQLServer/feedback/details/714968/provide-a-hint-to-force-generation-of-a-parallel-plan
Paul
Hi Paul,
I’m quite aware of why the HAVING clause is there, having put it there myself. And I’m also familiar with CROSS APPLY and JOIN semantics. I generally prefer the flexibility of the APPLY syntax.
As for what we really need, I believe I made the same point in the final couple of paragraphs of the article.
Thanks for sharing!
Adam
Right. Well I’m sure you were aware, it just didn’t come across to me in the main text. Perhaps I read it incorrectly. Anyway. Feel free to delete my comment if you feel it adds no value.
Hi Adam,
Can you elaborate why you are not doing this in C#, with CLR or on the client? Clearly you have spent a lot of time trying to make the optimizer do the right thing. You are saying yourself that you are not fully confident in this approach.
Would it not be cheaper/easier/simpler to just write and maintain your own execution plan in C# and be in full control, especially since "there are myriad other problems with SQL Server’s parallel processing capabilities"? Even if we need to invest in more hardware, that might still be much cheaper.
I am especially concerned about long term maintenance costs – how do I know if or when this workaround will stop working? If it does, an expert would need to be around and fix it. In my experience, changing C# code is usually much cheaper and needs less expertise.
What do you think?
Hi Alex,
It’s definitely an interesting question, but it’s not quite as easy as you make it sound. (At least, I don’t know how to make it easy.)
For me, doing parallelism work means that I’m dealing with large sets of data — maybe 100 million rows, maybe 1 billion rows. Moving that data to a client system for processing is not trivial. There are questions around data storage, maintenance, high availability, etc, etc. I’m sure some NoSQL solutions could be leveraged but that’s a complete change for a shop that uses SQL Server and "people time" isn’t free either.
I fully agree that in theory programming your own is better and probably easier. But once you dig in there are a number of obstacles that seem quite difficult to cross.
Do you think there’s a good general migration solution for this kind of thing?
–Adam
Adam,
I did not mean NoSQL at this time, I meant a smaller change: read SQL Server data from several threads, finalize the result set with CLR or C#. Instead of relying on SQL Server optimizer to choose a good parallel plan, let it do simpler tasks like reading and filtering. Do the more complex ones yourself.
Although this is not by any means easy, it might be easier, especially in the long term, after taking into account maintenance costs. Also it could be cheaper to throw some hardware than to pay for a top notch expert.
Alex,
Yes, I agree, and I’ve done similar things before.
But consider a typical data warehouse use case of reading a huge number of rows in order to produce an aggregate result. In this case your suggestion would require sending all of those rows over the network. Merely transferring those rows is going to incur a huge performance penalty; and that’s before you’ve even done any work with the data. Processing the data on the server means that the network hit is small. You’re just transferring the aggregate result.
It seems to me that any given solution is — until we have proper server-side support — highly dependent upon the specifics of the situation. Which is good for the top notch experts, I suppose. Not so good for people trying to find simple solutions.
Another potential option, perhaps? Spend a million dollars or so and buy a PDW. I have no clue whether it would reasonably solve any of these issues. (I doubt it.)
–Adam
Adam,
Maybe, just maybe, if you have a million dollars, you can ask small team of developers develop a customized NoSQL solution that will do exactly what you want. This may end up cheaper than struggling with a generic one.
Alex,
Quite possible. Kindly send me a million dollars and I’ll let you know how it works out.
Adam
Could you please come up with a solution to not enough memory grants under the parallel nested loops also for not even distributed data per driver key. In some cases a union all or a nested loop or pumped up data typed column helps but not always.
Thanks
Hi Gokhan,
I have some solutions for those problems but they’re much more case-specific and are difficult to write about in a blog format. So don’t hold your breath 🙂
–Adam
Adam, really interesting! I’m trying to make sure my testing isn’t caching, but on my limited test (2-way join on a table with 1.3 billion rows) it runs in about half the time, with roughly the same number of reads. (multiple runs in different order to eliminate/standardize caching).
Hi Adam,
really interesting and educational, you made me think about some new solution to performance problems, enjoyed hearing you on SQL DOWN UNDER.
keep up the great work.
and thanks for the blog posts.
Yoni Nakache.
Nice one, co-incidentally i have been playing with the reverse thought after dealing with SQL CLR.
The reverse thought being to introduce a few NOP (No operation) functions that are marked as non-deterministic. Which can as you have shown before in an older blog be helpful in improving/guiding plans.
In its simplest form you have a scalar method returning always 0, being marked non-deterministic. To apply it you simply add the outcome to some other number you want to behave as non-deterministic as well. Same can be done for for strings etc, using an empty string…i am sure adding empty strings to a non-empty one will internally be optimized to have minimal overhead.
Funny enough I came on this idea because i noticed the large number of needless parallel plans when dealing with SQL CLR table valued functions. The number of records expected from a table valued SQL CLR function is always 1000 when not wrapping the call in an explicit top operator. This default estimation leads to large memory grands and parallel plans, even when it is obviously pure overhead and will slow processing down.
On a similar note, you might be able to do what you do in this blog article by using a SQL CLR function with a deliberate large top operator.
That way you can simply return one or even zero records and get the same result as the optimizer has no other information about what is likely to go on in the function, then what your top operator tells it to!
An obvious application of top-operator manipulation of SQL CLR methods is a string split of an ID list. A caller will nearly always know the number of elements present in the list, and if not, can cheaply find this out. On the SQL side methods should be written in a way to exploit this information to come up with appropriate plans.
One correction to my first post. It turns out it was Paul White that wrote a blog about using non-deterministic SQL functions to alter execution plan behavior a while back:
http://sqlblog.com/blogs/paul_white/archive/2012/09/05/compute-scalars-expressions-and-execution-plan-performance.aspx
The idea remains the same, assist or guide the optimizer to get to the plan you want.
I watched your presentation, and it has some pretty neat stuff in there, thanks for that! Still the reason I do not bet heavy on in-query parallelism in my work is that many, if not all SQL Server versions to date have a serious bug in this area.
I do not have the link at hand here, but if my memory serves me, it comes down to a top operator not always stopping no longer needed "feeding" operators, causing them to run way longer then required. This for example happens with cross joins over a synthetic "union all" driver table, that gets subsequently "topped". The heavier parallelism you allow on a server, the more frequent this problem kicks in (be it with certain queries).
None of your example queries in the demonstration fall in this category i think, because none relies on TOP(N) limiting rows far below what otherwise would be the output. But for a whole server, it is risky and certainly something to keep in mind and be aware off.
@Peter
Regarding the idea of using a CLR function, I have two thoughts: A) I don’t need to mess with determinism very often (although it does come up from time to time), and B) when I do, I can use NEWID(). Is a CLR function actually going to be faster/better in some way?
CLR TVFs have an output estimate of 1000, always – so there is no way to use a large TOP in that case, nor to add any additional information about the number of elements in a string. I actually have another blog post, coming soon, about how to mess with row estimates. Stay tuned 🙂
There are some parallelism bugs but they are much less commonly encountered, in my experience, than what you seem to be indicating. I’ve been very heavily working with parallelism in SQL Server for the past five or six years, including on systems with quite a bit of load, and I’ve only seen the issue you’re referring to a handful of times. When I have seen it, it has been in dev environments, during testing. I’ve never seen a query suddenly hit the problem in production. So my concern about that particular aspect of parallelism is near zero. There are some other issues that DO cause production problems — primarily having to do with how SQL Server handles thread scheduling — but in most cases they’re not total deal breakers.
–Adam
Adam,
I witness every time that when i wrap a CRL function in a top, it will listen to that estimate. The way CLR table-valued functions are iterated trough is uni-directional from first to last record. There is no other way to get to the 2nd output row then by iterating over the first.
This means that when you enclose the call in like a manual sub select with a top or wrap this sub select in another inline TVF, the optimizer really estimates the number or rows as specified in the top…there is no other information to go by.
I seen this time and time again…1000 is i think the default used for when there is no other information available. Just like it always estimates 1 for table variables.
As for newID() i think it does too much to be used as a "no operation". Even to use it as such, you need to incorporate it in yet more SQL functions (like left)…adding cost and complexity. It looks easier and is most likely faster to just concat a non-deterministic string. I am not even saying the string has to come from a CLR function, just saying it has to be involved to copy the non-deterministic property.
I will make some examples and benchmark them before i have to work again next year. I got a few days of "me time" still coming :).
As for the parallelism bugs, there are a few cases yes. The one i was more talking about is the one popping up with SQL string splitting. It is only recent that i started working with SQL CLR and now i am designing a small library of base functions bases on what I learned about it. There are some nice new insights and some alarm bells too with respect to code i seen before. One really has to pay close attention to the SQL / CLR interface and not shuffle data if you can avoid it…especially stings.
Once it is ready, I may write something about it. What i can tell is that they made a blunder if you ask me in some regards. Most notably the collation passed with (SQL) strings in arguments. It uses the collation of the database for example instead of the collation of the column or operation result you pass to a function. Making it instantly useless complexity and integration half baked.
It has some nice things too of course and the less known C# Yield statement saves a ton of work :). I am sure we talk in more detail in coming months.
@Peter
Yes, you can go LOWER, but never above 1000. I just confirmed that on this end. If you have a way to get it above 1000 I would definitely appreciate a complete repro. E-mail if it’s too large to post here. adam [at] sqlblog [dot] com.
–Adam
You are right Adam, I just tested it as well, lower works, higher does not. The last few hours I also tried to "streamline" your code in order to not get mega sub-tree costs and still enjoy the results.
In principle, all you need it to raise the cost of the serial plan just above the server threshold for parallelism, and that will be good to force the parallel plan. That said, a sub-tree cost of over 700.000 as in the demo code is way out of bounds of my liking and will lead confusion when examining plans of other peoples queries (in my case).
Without much more comments, here is the new code…it uses C# for the row driver and abuses the 1000 row estimate to its potential 🙂
create function dbo.make_parallel2()
returns table as
return
(
select
IgnoreMakeParallel = 1
from
(
select top ( 9223372036854775807 )
SumValue = sum( a.Value ) + sum( b.Value )
from
dbo.OneRow_Int() as a
, dbo.OneRow_Int() as b
, dbo.OneRow_Int() as c
)
as dr
where
dr.SumValue = 0
)
;
go
The C# code for the row driver…you know how to handle this 🙂
public partial class Math
{
public static void OneRow_Int_SQLFillRow( object obj, out int value )
{
value = 0;
}
// Return one row with Value 0
[SqlFunction
(
Name = "OneRow_Int"
, FillRowMethodName = "OneRow_Int_SQLFillRow"
, TableDefinition = "Value Int"
, IsDeterministic = false
, IsPrecise = true
)
]
public static IEnumerator OneRow_Int()
{
// Return one result before implicit "yield break".
// This return does not need to be an object instance because FillRowMethod returns constants!
yield return null;
}
}
This is the same version, but with the option to better tune the plan cost to the server parallelism threshold:
create function dbo.make_parallel3()
returns table as
return
(
select
IgnoreMakeParallel = 1
from
(
select top ( 9223372036854775807 )
SumValue = sum( a.Value ) + sum( b.Value )
from
dbo.OneRow_Int() as a
, dbo.OneRow_Int() as b
— Add/remove "union all select 0" to make the cost of following statement more/bigger then the "cost threshold for parallelism" server setting : select * from dbo.make_parallel3() option( maxdop 1 );
, (
select 0 union all select 0 union all select 0 union all select 0 union all select 0 union all
select 0 union all select 0 union all select 0 union all select 0 union all select 0
)
as c ( Value )
)
as dr
where
dr.SumValue = 0
)
;
go
Here the version without any large list of constants:
alter function dbo.make_parallel4()
returns table as
return
(
select
IgnoreMakeParallel = 1
from
(
select top ( 9223372036854775807 )
SumValue = sum( a.Value ) + sum( b.Value )
from
dbo.OneRow_Int() as a
, dbo.OneRow_Int() as b
/* Decrease/Increase top operator to make the cost of following statement
bigger then the "cost threshold for parallelism" server setting:
select * from dbo.make_parallel4() option( maxdop 1 );
*/
, ( select top 8 Value from dbo.OneRow_Int() ) as c
)
as dr
where
dr.SumValue = 0
)
;
go
I also noted that it is possible to introduce a hash operation with a memory grant. But since there is only one record anyways, ever…i don’t think that memory is actually claimed. Could this property be exploited to tune queries that spill due to small a memory grant?
I don;t know about the gory internals here, but you probably do!
Interestingly that latest version turns out to be faster too. Likely due to not needing to process 1024 rows in order to mislead the optimizer. I also noticed that it has one less parallel operator in there too, which reduces spawning threads for something that does not need to process volume in practice.
Here is a screenshot of a query that running 15 times on a ‘warm’ system:
http://clip2net.com/s/6uYCFu
I ran it 33 times, sorry, so don’t be confused about that :).
I am interested in what your finding will be…if you got the time to try it.
@Peter
Nice work.
However, all of that code and infrastructure to shave a few milliseconds off of a query? … I would only use this on really large queries anyway — stuff that takes a lot longer than 1 second to run. (My biggest real production queries sometimes take 2-3 *hours*, and that’s after I’ve tuned ’em every possible way I know of.) I applaud your effort, but it’s just not for me 🙂
If you want something cheaper but in one unit, simply cut down on the number of rows in [a0] in my sample code. Did you try that? It will proportionally reduce the cost as well as the run time, so you can tune or tweak to your liking that way. You might be able to put a second TOP a bit deeper in, parameter-driven, so as to control the cost and behavior on a more granular level. That would be interesting, but again, not something I personally care about. I don’t ever look at query cost when I’m tuning — it’s just an estimate and tells me very little about reality — so these outliers aren’t going to show up on my reports.
As for the memory grant: No, it won’t help. The memory grant is calculated (and later granted) on a per-operator basis, so having more memory for the overall plan won’t help unless that memory is applied in the right places.
Stay tuned, as I said before. An upcoming blog post will shed more light on some of this.
–Adam
Hi Adam,
I tried cutting down the row-driver and that is exactly what i benched against :). I wasn’t really out to set a speed record, but more to get the visual execution plan cleaner (which is surprisingly hard as i never succeeded by using just 2 joins).
The server loads I have to deal with are noting like what you describe, but they are often latency sensitive…as in user does not like to wait. I am betting on utilizing this technique and the one you presented in your presentation quite frequently as it fits the nature of our workloads quite well. And after upping the threshold for parallelism, forcing it when needed is a piece of code that will play a role too. We also are using SSDs in all our newer servers, which means random access is less of an issue and that makes the technique just more effective i figure. Less need for a full scan, multiple smaller ones will do just as good and that makes using all the cores efficiently also easier.
The last idea which i played with is to make the method a bit more conventional by wrapping it up in a view instead of a parameter less inline table function. Somehow that fits the bill better :).
A completely ridiculous yet useful in some situations (e.g. admin privilege and parallel cost threshold immune query) workaround.
It is likely sad in terms of efficiency how much effort you had to invest when compared to the MS developer that has yet to implement this feature.
Hey Adam,
First, I love the function – it’s absolutely brilliant. I have playing around with it since you posted it and thought I’d share a recent success story.
This week I created a "pattern replace" function that replaces characters based on a pattern (e.g. SELECT * FROM patreplace8k(‘123xyz’,'[a-z]’,’!’) returns: 123!!!). There are a couple examples in the comment part of the code.
Anyhow, make_parallel() doubles the speed.
THE FUNCTION:
——————————————————–
CREATE FUNCTION dbo.PatReplace8K
(
@String VARCHAR(8000),
@Pattern VARCHAR(50),
@Replace CHAR(1)
)
/*
–Use:
— mask a value
SELECT *
FROM dbo.PatReplace8K(‘my credit card number is: 5555-1234-7777-8888′,'[0-9]’,’*’);
— extract a phone number
SELECT *
FROM dbo.PatReplace8K(‘Call me at: 555-123-9999′,'[^0-9-]’,”);
GO
*/
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
WITH E1(N) AS (SELECT N FROM (VALUES (NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL),(NULL)) AS E1(N)),
Tally(N) AS (SELECT TOP (LEN(@String)) CHECKSUM(ROW_NUMBER() OVER (ORDER BY (SELECT NULL))) FROM E1 a,E1 b,E1 c,E1 d)
SELECT NewString =
CAST
(
(
SELECT CASE
WHEN PATINDEX(@Pattern,SUBSTRING(@String COLLATE Latin1_General_BIN,N,1)) = 0
THEN SUBSTRING(@String,N,1)
ELSE @replace
END +”
FROM Tally
FOR XML PATH(”), TYPE
)
AS varchar(8000)
);
GO
THE TEST:
——————————————————–
–===== Create the 100K row test table
IF OBJECT_ID(‘tempdb..#val’) IS NOT NULL DROP TABLE #val;
SELECT TOP 100000
txt = ISNULL(CONVERT(VARCHAR(36),NEWID()),”)
INTO #val
FROM sys.all_columns ac1
CROSS JOIN sys.all_columns ac2;
ALTER TABLE #Val
ADD PRIMARY KEY CLUSTERED (txt);
GO
PRINT ‘========== Using PatReplace8K ==========’;
DECLARE @String VARCHAR(36)
,@StartTime DATETIME;
SELECT @StartTime = GETDATE();
SELECT @string = newstring
FROM #val
CROSS APPLY dbo.PatReplace8K(txt, ‘[^0-9]’,”)
PRINT DATEDIFF(ms,@StartTime,GETDATE());
GO 3
PRINT ‘========== Using PatReplace8K with make_parallel() ==========’;
DECLARE @String VARCHAR(36)
,@StartTime DATETIME;
SELECT @StartTime = GETDATE();
SELECT @string = newstring
FROM #val
CROSS APPLY dbo.PatReplace8K(txt, ‘[^0-9]’,”)
CROSS APPLY dbo.make_parallel();
PRINT DATEDIFF(ms,@StartTime,GETDATE());
GO 3
THE RESULTS:
——————————————————–
Beginning execution loop
========== Using PatReplace8K ==========
2726
========== Using PatReplace8K ==========
2730
========== Using PatReplace8K ==========
2636
Batch execution completed 3 times.
Beginning execution loop
========== Using PatReplace8K with make_parallel() ==========
1386
========== Using PatReplace8K with make_parallel() ==========
1386
========== Using PatReplace8K with make_parallel() ==========
1550
Batch execution completed 3 times.
Would there be any benefit here to changing
SELECT a0.*
to
SELECT a0.x
and then using WITH SCHEMABINDING on the function definition?
@John #2
It’s unlikely to help. The cases where that does have some impact tend to be with scalar UDFs and certain types of update plans.(Sans underlying schema to which the function can actually bind, which is a different story altogether.)
–Adam
This is a much better alternative. I’ve used it to take a query from 3:34 to 0:09. Meanwhile, I don’t have to change any of the other site-wide settings just to get speed boost in one area while I’m investigating why this particular sproc all of a sudden slowed down.
Comments are closed.