Working with hierarchies in SQL Server never fails to be absolutely fascinating.
On the face of things they’re super-easy to model and seem to fit perfectly well: parent_key, child_key, self-referencing FK, and you’re done. But then you go to query the thing and there is a complete breakdown.
Prior to SQL Server 2005 the product included zero language support for hierarchical navigation. That release gave us the recursive CTE, a feature which perhaps could have solved all of our issues. But alas, its implementation is notoriously heavy and sluggish.
As a result of the language gap, various smart and creative people have come up with lots of interesting and alternative ways of modeling hierarchies. These include materialized (enumerated) path models, nested sets, nested intervals, and of course SQL Server’s own HierarchyId data type. Each of these techniques involves deep understanding, often some interesting math, and lots of work to get right. Just the kind of thing that usually keeps me fully engaged.
But this post isn’t about any of these alternative models. This post is about standard, run-of-the-mill adjacency lists. I’m a big fan of the adjacency list, if only for the fact that I can put one together without breaking out the espresso machine. If only the performance problems could be fixed, perhaps we could leverage them in a wider variety of scenarios.
Important notes:
- First of all, you might want to review my PASS Summit 2014 presentation on parallelism techniques prior to continuing with this post. The content below builds heavily on many of the ideas I introduced in that session.
- Second, you might (rightfully) decide that my reasoning is flawed, and that’s fine: I’m advocating for adjacency lists because of simplicity, and some of the queries below are somewhat less than simple. We all need to pick our own favorite poisons.
- Finally, please be aware that these techniques have been heavily tested, but not rigorously tested. This is more of a research topic for me than something I would recommend as a “best practice,” and there very well may be bugs and/or caveats that I have yet to uncover.
Why are we here?
Several months ago on a mailing list I subscribe to, there was a long thread on hierarchies and hierarchical modeling. The thread was initially about HierarchyId but eventually morphed into a discussion on various other hierarchy techniques. Much of the thread was devoted to how annoying HierarchyId is to work with, and how annoying it is that adjacency lists can’t perform well.
This thread sparked a set of questions in my mind: What’s wrong with a simple adjacency list? Why are recursive CTEs not better at doing their job? And is there any way to improve the situation?
After giving the issue some thought I decided to try to apply some of the techniques I’ve been developing for optimizing parallel query plans. The result? Well, read on…
Hierarchical Modeling, the Adjacency List, and Recursive CTEs
“Every employee has a manager. So every employee’s row references his manager’s row. Except the CEO; that row has a NULL manager since the CEO doesn’t report to any of our employees.”
Say that sentence to any technology person, any business person, any pointy-haired boss type, and right away they’ll get exactly what you mean. They’ll understand the model. And if your company hasn’t adopted some weird matrix management approach, it will fit. It’s a simple and absolutely perfect way to model simple reality. It’s the adjacency list.
And not only is modeling the data easy, data management is just as simple. Need to insert a new middle manager somewhere along the line? Just insert a row and update a few other rows. Need to remove someone? Reverse that process.
So why, then, do we play games and attempt to use other models? Fire up your favorite hierarchy and ask for a report, with full materialized paths, of everyone who reports up to the CEO. (In the code attached to this post you’ll find two test hierarchies, one wide and one deep. The wide hierarchy has 1,111,111 nodes in only 7 levels. The deep hierarchy has slightly fewer nodes—1,048,575—but it’s 20 levels deep.)
More than likely—if you’re current with your T-SQL skills—you’ll write a query like this one:
WITH
paths AS
(
SELECT
EmployeeID,
CONVERT(VARCHAR(900), CONCAT('.', EmployeeID, '.')) AS FullPath
FROM EmployeeHierarchyWide
WHERE
ManagerID IS NULL
UNION ALL
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT(p.FullPath, ehw.EmployeeID, '.'))
FROM paths AS p
INNER JOIN EmployeeHierarchyWide AS ehw ON
ehw.ManagerID = p.EmployeeID
)
SELECT
*
FROM paths
This query materializes the path, separating node (employee) IDs using periods, by leveraging a recursive CTE. It returns the desired results, but at a cost: This version, which operates on the wide test hierarchy, takes just under 10 seconds on this end, run in Management Studio with the Discard Results After Execution option set.
Depending on your typical database style—transaction processing vs. analytical—10 seconds is either a lifetime or doesn’t sound too bad. (I once interviewed a career OLTP developer who told me that no query, in any database, ever, should run for longer than 40ms. I told the company to not hire her for the data warehouse developer position she was interviewing for. I believe her head would have quite literally exploded, right in the middle of her second heart attack, about an hour before lunch on her first day.)
Once you reset your outlook on query times to something a bit more realistic, you might notice that this isn’t a gigantic amount of data. A million rows is nothing these days, and although the rows are artificially widened—the table includes a string column called “employeedata” that contains between 75 and 299 bytes per row—only 8 bytes per row are brought into the query processor on behalf of this query. 10 seconds, while quite brief for a big analytical query, should be sufficient time to answer much more complex questions than that which I’ve posed here. So based purely on the metric of Adam’s Instinct and Gut Feel, I hereby proclaim that this query feels significantly too slow.
Just like other queries, understanding the performance characteristics of this one requires a peek at the execution plan:
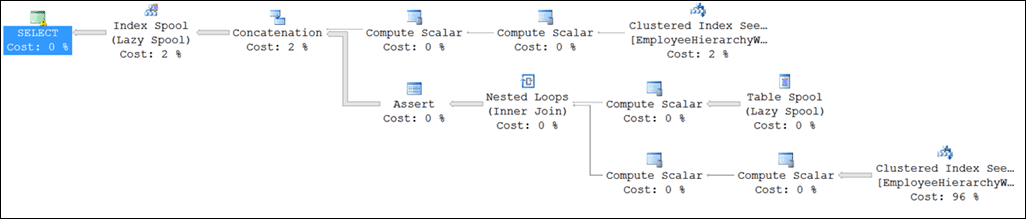
In this plan, the anchor part of the CTE is evaluated on the upper subtree under the Concatenation operator, and the recursive part on the lower subtree. The “magic” that makes recursive CTEs work is contained within the Index Spool seen at the upper left part of the image. This spool is, in fact, a special version that allows rows to be dropped in and re-read in a different part of the plan (the Table Spool operator which feeds the Nested Loop in the recursive subtree). This fact is revealed with a glance at the Properties pane:
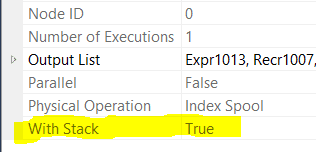
The spool in question operates as a stack—a last in, first out data structure—which explains the somewhat peculiar output ordering we see when navigating a hierarchy using a recursive CTE (and not leveraging an ORDER BY clause):
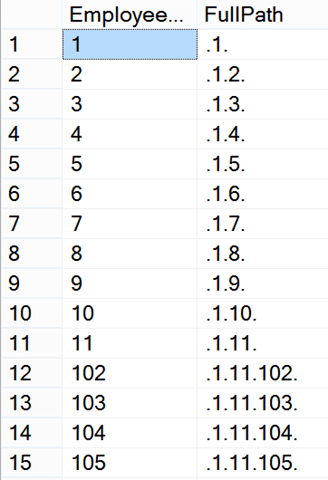
The anchor part returns EmployeeID 1, and the row for that employee is pushed (i.e. written) into the spool. Next, on the recursive side, the row is popped (i.e. read) from the spool, and that employee’s subordinates—EmployeeIDs 2 through 11—are read from the EmployeeHierarchyWide table. Due to the index on the table, these are read in order. And because of the stack behavior, the next EmployeeID that’s processed on the recursive side is 11, the last one that was pushed.
While these internals details are somewhat interesting, there are a few key facts that explain both performance (or lack thereof) and some implementation hints:
- Like most spools in SQL Server, this one is a hidden table in tempdb. This one is not getting spilled to disk when I run it on my laptop, but it’s still a heavy data structure. Every row in the query is effectively read from one table and then re-written into another table. That can’t possibly be a good thing from a speed perspective.
- Recursive CTEs cannot be processed in parallel. (A plan containing a recursive CTE and other elements may be able to use parallelism for the other elements—but never for the CTE itself.) Even applying trace flag 8649 or using my make_parallel() function will fail to yield any kind of parallelism for this query. This greatly limits the ability for this plan to scale.
- The parallelism limitation is especially interesting because it is not necessary. Why, for example, can’t one thread process the subordinates of EmployeeID 11, while a second thread processes the subordinates of EmployeeID 10?
- The stack behavior, likewise, doesn’t really matter. Do you care whether EmployeeID 11 is processed prior to EmployeeID 10? Would this change the output in any meaningful way? Of course not. The stack was no doubt chosen because it’s a simple data structure for solving the problem at hand, but from an implementation standpoint a queue would have been equally effective.
I like the idea of adjacency lists, and I like the idea of recursive CTEs. They’re easy to understand and easy to maintain. To go faster we must both eliminate tempdb from the equation and remove the limitations on parallel query plans. And using the built-in functionality, that’s just not going to happen. Solution? Roll our own.
hierarchy_navigator: The SQLCLR Recursive CTE
After consideration of the four facts outlined in the previous section, I realized that it would be fairly simple to create a “recursive CTE” library in C#. By doing so I would be able to eliminate many of the issues with T-SQL recursive CTEs and take full control over processing.
My core thought was that by creating my own data structures I could eliminate much of the tempdb overhead inherent with T-SQL recursive CTEs. There would naturally be transfer and allocation overhead as part of moving the data into the CLR space, but I felt that I could optimize things to the point where that cost would still be far less than what the query processor has to do in order to maintain a spool. The tradeoff is of course memory, and that’s something I feel is worth sacrificing for better performance. As always, you should make your own decisions on those kinds of issues based on your applications and workloads.
The data structure I decided to work with was a lock-free queue. Why a queue instead of a stack? Because I had already written the queue for something else. As mentioned above, this is merely an implementation detail. It should not matter to you in what order the data is processed, nor in what order it is output, in the absence of an ORDER BY clause.
The main benefit of a lock-free queue? Since it’s naturally thread safe it inherently supports parallelism. And since it’s lock-free my CLR assembly can be cataloged as SAFE, a nice benefit especially now that SAFE CLR assemblies are supported in Azure SQL Database.
Writing the queue in C# is one thing; getting the query processor to use it is a slightly more arduous task. My initial thought was to create a system that would support queries of a form similar to the following:
SELECT
i.EmployeeID,
i.FullPath
FROM
(
SELECT
EmployeeID,
CONVERT(VARCHAR(900), CONCAT('.', EmployeeID, '.')) AS FullPath
FROM EmployeeHierarchyWide
WHERE
ManagerID IS NULL
UNION ALL
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT(hi.FullPath, ehw.EmployeeID, '.'))
FROM dbo.hierarchy_inner(@@SPID) AS hi
INNER JOIN EmployeeHierarchyWide AS ehw ON
ehw.ManagerID = hi.EmployeeID
) AS i
CROSS APPLY dbo.hierarchy_outer(@@SPID, i.EmployeeID, i.FullPath) AS ho
The idea here was to make the query feel more or less “recursive CTE-esque.” Each row from the derived table [i] (which is really just a modified recursive CTE) would push values into the hierarchy_outer() TVF. This TVF would then internally enqueue the EmployeeID and path and subsequently output a row. (Any row would be fine—the presence of a row is what would matter, not its content, so the idea was for the function to output an integer column called “x” that always had a value of 0.) On the “recursive” part of the query, the hierarchy_inner() function could dequeue an EmployeeID and path, driving a seek into EmployeeHierarchyWide, which would then feed the hierarchy_outer() function, and so on and so forth.
Each of the functions in this design takes a SQL Server session_id as an argument, in order to appropriately scope the memory allocation required to handle passing of values around on the lock-free queue.
Part of this design required setting up some internal synchronization logic in the functions. It is to be expected that at various points the internal queue may not have enough of a backlog to keep all of the worker threads busy, and we wouldn’t want the threads without enough work to do to shut down until the entire process is actually complete. In order to facilitate this, I implemented logic as explained by the following flowchart:
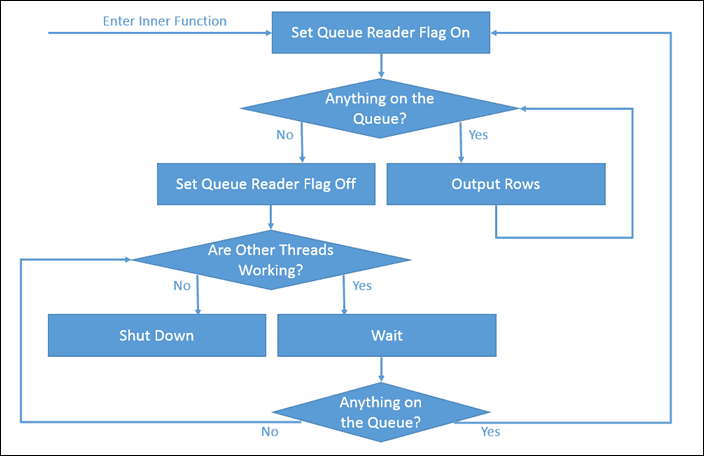
In this scheme each thread sets a central flag (actually a counter) upon entering the function. If a thread begins outputting rows from the queue (and, therefore, reading from the recursive side and potentially pushing more rows onto the queue), that flag will stay set, indicating that any other threads should not shut down even if they have no work to do. The threads that are waiting will yield until either some work appears on the queue, or all of the other threads have set the reader flag off, thereby indicating that no work is forthcoming.
Once coded and deployed, at first blush everything seemed great. The query optimizer produced a perfect serial plan:

This plan had exactly the correct shape, with exactly the correct behaviors. And reducing the tempdb overhead helped tremendously: this plan ran in only 6.5 seconds, 45% faster than the recursive CTE.
Alas, making this into a parallel query was not nearly as easy as simply applying TF 8649. As soon as the query went parallel myriad problems cropped up. The query optimizer, having no clue what I was up to, or the fact that there was a lock-free data structure in the mix, started trying to “help” in various ways…
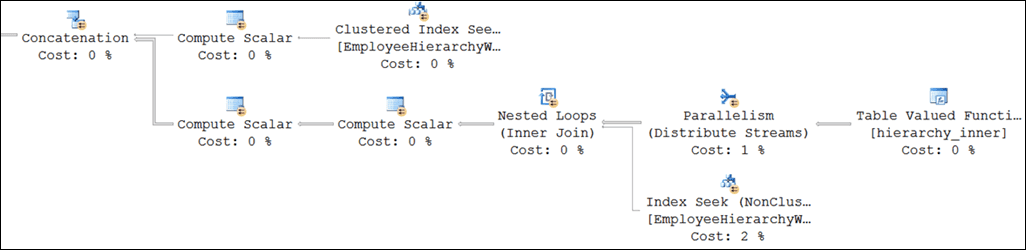
This plan might look perfectly decent to the casual observer. Almost the same shape as before, except for that Distribute Streams iterator, whose job it is to parallelize the rows coming from the hierarchy_inner() function. This would have been perfectly fine if hierarchy_inner() were a normal function that didn’t need to retrieve values from downstream in the plan via an internal queue, but that latter condition creates quite a wrinkle.
The reason this didn’t work? In this plan the values from hierarchy_inner() must be used to drive a seek on EmployeeHierarchyWide so that more rows can be pushed into the queue and used for latter seeks on EmployeeHierarchyWide. But none of that can happen until the first row makes its way down the pipe. This means that there can be no blocking iterators on the critical path. If anything blocks that critical first output row from being used for the seek, or those latter rows from driving more seeks, the internal queue will empty and the entire process will shut down. And unfortunately, that’s exactly what happened here. Distribute Streams is a “semi-blocking” iterator, meaning that it only outputs rows once it amasses a collection of them. (That collection, for parallelism iterators, is known as an Exchange Packet.)
Phrased another way, the semi-blocking behavior created a chicken-and-egg problem: The plan’s worker threads had nothing to do because they couldn’t get any data, and no data could be sent down the pipe until the threads had something to do. I considered modifying the hierarchy_inner() function to output specially marked junk data in these kinds of situations, in order to saturate the Exchange Packets with enough bytes to get things moving, but that seemed like a dicey proposition. I was unable to come up with a simple algorithm that would pump out only enough data to kick off the process, and only fire at appropriate times. (Such a solution would have to kick in for this initial state problem, but should not kick in at the end of processing, when there is truly no more work left to be done.)
The only solution, I decided, was to eliminate all blocking iterators from the main parts of the flow—and that’s where things got just a bit more interesting.
The Parallel APPLY pattern that I have been speaking about at conferences for the past few years works well partly because it eliminates all exchange iterators under the driver loop, so was is a natural choice here. Combined with the initializer TVF method that I discussed in my PASS 2014 session, I thought this would make for a relatively easy solution:
SELECT
p.*
FROM
(
SELECT DISTINCT
x
FROM dbo.hierarchy_simple_init(@@SPID)
) AS v
OUTER APPLY
(
SELECT
i.EmployeeID,
i.FullPath
FROM
(
SELECT
EmployeeID,
CONVERT(VARCHAR(900), CONCAT('.', EmployeeID, '.')) AS FullPath
FROM EmployeeHierarchyWide
WHERE
ManagerID IS NULL
UNION ALL
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT(hi.FullPath, ehw.EmployeeID, '.'))
FROM dbo.hierarchy_inner(v.x, @@SPID) AS hi
INNER JOIN EmployeeHierarchyWide AS ehw ON
ehw.ManagerID = hi.EmployeeID
) AS i
CROSS APPLY dbo.hierarchy_outer(@@SPID, i.EmployeeID, i.FullPath) AS ho
) AS p
WHERE
p.EmployeeID IS NOT NULL
To force the execution order I modified the hierarchy_inner function to take the “x” value from the initializer function (“hierarchy_simple_init”). Just as in the example shown in the PASS session, this version of the function output 256 rows of integers in order to fully saturate a Distribute Streams operator on top of a Nested Loop.
Once applying TF 8649 I discovered that the initializer worked quite well—perhaps too well. Upon running this query rows started streaming back, and kept going, and going, and going…

The issue? The anchor part must be evaluated only once, even if there are numerous threads involved in the query. In this case I built no protection against it being evaluated multiple times, so the query processor did exactly as I asked and evaluated it 256 times—once per initializer row. As a result, my query produced 256 times more rows than were needed; definitely not the desired output.
My solution for this was to create yet another function, this one to operate as part of the anchor:
SELECT
p.*
FROM
(
SELECT DISTINCT
x
FROM dbo.hierarchy_simple_init(@@SPID)
) AS v
OUTER APPLY
(
SELECT
i.EmployeeID,
i.FullPath
FROM
(
SELECT
EmployeeID,
CONVERT(VARCHAR(900), CONCAT('.', EmployeeID, '.')) AS FullPath
FROM dbo.hierarchy_anchor(v.x, @@SPID) AS ha
CROSS JOIN EmployeeHierarchyWide
WHERE
ManagerID IS NULL
UNION ALL
SELECT
ehw.EmployeeId,
CONVERT(VARCHAR(900), CONCAT(hi.FullPath, ehw.EmployeeID, '.'))
FROM dbo.hierarchy_inner(v.x, @@SPID) AS hi
INNER JOIN EmployeeHierarchyWide AS ehw ON
ehw.ManagerID = hi.EmployeeID
) AS i
CROSS APPLY dbo.hierarchy_outer(@@SPID, i.EmployeeID, i.FullPath) AS ho
) AS p
WHERE
p.EmployeeID IS NOT NULL
The function hierarchy_anchor() shown in this version of the query was designed to use the exact same signature as the hierarchy_inner() function, but without the need to touch the queue or anything else internal except a counter to ensure that it would return one, and only one row, per session.
It almost worked!
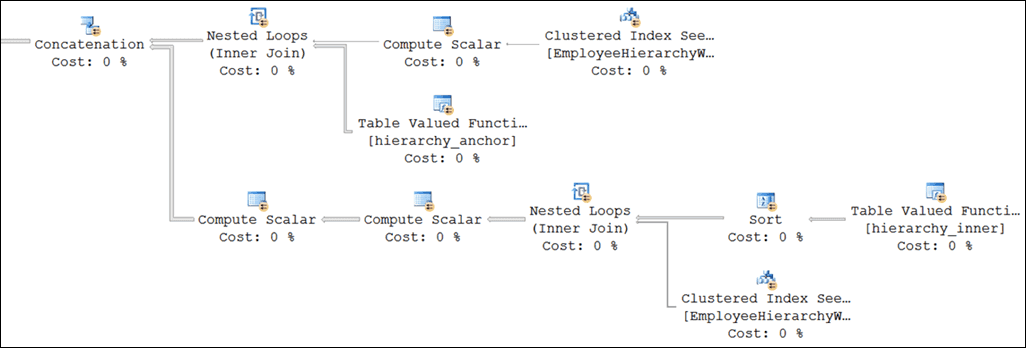
The optimizer decided to push the hierarchy_anchor() function call under the anchor EmployeeHierarchyWide seek, which means that that seek would be evaluated 255 more times than necessary. That could have been considered a flaw, but at this point I was okay with it because each of those 255 seeks were comparatively inexpensive. The anchor part still returned only one set of actual output rows, by virtue of the function filtering things out. So far so good.
Unfortunately, changing the characteristics of the anchor part also had an impact on the recursive part. The optimizer introduced a sort after the call to hierarchy_inner(), which was a real problem.
The idea to sort the rows before doing the seek is a sound and obvious one: By sorting the rows by the same key that will be used to seek into a table, the random nature of a set of seeks can be made more sequential. In addition, subsequent seeks on the same key will be able to take better advantage of caching. Unfortunately, for this query these assumptions are wrong in two ways. First of all, this optimization should be most effective when the outer keys are nonunique, and in this case that is not true; there should only be one row per EmployeeID. Second, Sort is yet another blocking operator, and we’ve already been down that path.
Once again the issue was that the optimizer doesn’t know what’s actually going on with this query, and there was no great way to communicate. Getting rid of a sort that has been introduced due to this type of optimization requires either a guarantee of distinctness or a one-row estimate, either of which tell the optimizer that it’s best not to bother. The uniqueness guarantee is impossible with a CLR TVF without a blocking operator (sort/stream aggregate or hash aggregate), so that was out. One way to achieve a single-row estimate is to use the (admittedly ridiculous) pattern I showed in my PASS 2014 session:
SELECT
p.*
FROM
(
SELECT DISTINCT
x
FROM dbo.hierarchy_simple_init(@@SPID)
) AS v
OUTER APPLY
(
SELECT
i.EmployeeID,
i.FullPath
FROM
(
SELECT
EmployeeID,
CONVERT(VARCHAR(900), CONCAT('.', EmployeeID, '.')) AS FullPath
FROM dbo.hierarchy_anchor(v.x, @@SPID) AS ha
CROSS JOIN EmployeeHierarchyWide
WHERE
ManagerID IS NULL
UNION ALL
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT(hi.FullPath, ehw.EmployeeID, '.'))
FROM dbo.hierarchy_inner(v.x, @@SPID) AS hi
CROSS APPLY (SELECT SUM(id) FROM (VALUES(hi.EmployeeID)) AS p0 (id)) AS p(y)
CROSS APPLY (SELECT SUM(id) FROM (VALUES(hi.EmployeeID)) AS p0 (id)) AS q(y)
INNER JOIN EmployeeHierarchyWide AS ehw ON
ehw.ManagerID = hi.EmployeeID
WHERE
hi.EmployeeID = p.y
AND hi.EmployeeID = q.y
AND hi.EmployeeID = CHECKSUM(hi.EmployeeID)
) AS i
CROSS APPLY dbo.hierarchy_outer(@@SPID, i.EmployeeID, i.FullPath) AS ho
) AS p
WHERE
p.EmployeeID IS NOT NULL
The nonsense (and no-op) CROSS APPLYs combined with the nonsense (and once again no-op) predicates in the WHERE clause rendered the desired estimate and eliminated the sort in question:
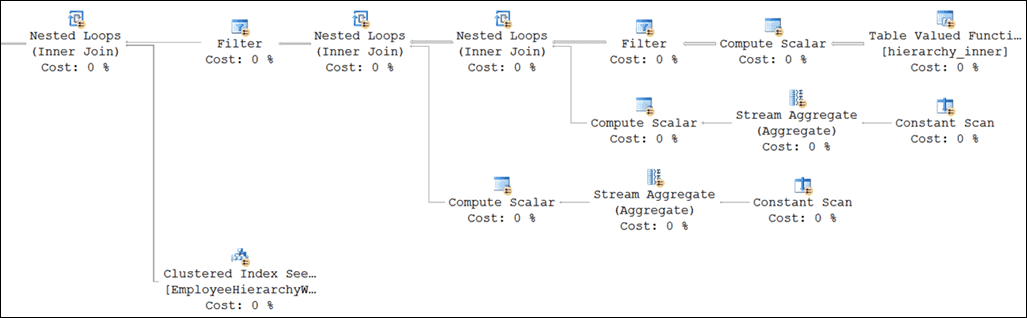
Unfortunately, zooming out a bit revealed that other parts of the plan were also impacted:
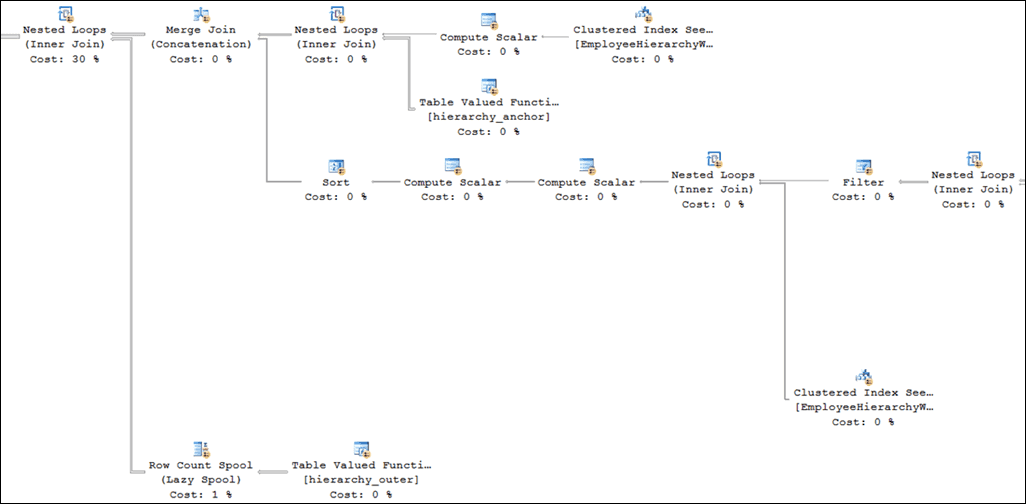
The Concatenation operator between the anchor and recursive parts was converted into a Merge Join, and of course merge requires sorted inputs—so the Sort had not been eliminated at all. It had merely been moved further downstream!
To add insult to injury, the query optimizer decided to put a Row Count Spool on top of the hierarchy_outer() function. Since the input values were unique the presence of this spool would not pose a logical problem, but I saw it as a useless waste of resources in this particular case, as it would never be rewound. (And the reason for both the Merge Join and the Row Count Spool? The same exact issue as the prior one: lack of a distinctness guarantee and an assumption on the optimizer’s part that batching things would improve performance.)
After much gnashing of teeth and further refactoring of the query, I managed to bring things into a working form:
SELECT
p.*
FROM
(
SELECT DISTINCT
x
FROM dbo.hierarchy_simple_init(@@SPID)
) AS v
CROSS APPLY
(
SELECT
i.EmployeeID,
i.FullPath
FROM
(
SELECT
anchor.*
FROM
(
SELECT TOP(1)
*
FROM dbo.hierarchy_anchor(v.x, @@SPID) AS ha0
) AS ha
CROSS APPLY
(
SELECT
EmployeeID,
CONVERT(VARCHAR(900), CONCAT('.', EmployeeID, '.')) AS FullPath
FROM EmployeeHierarchyWide
WHERE
ManagerID IS NULL
) AS anchor
UNION ALL
SELECT
recursive.*
FROM dbo.hierarchy_inner(v.x, @@SPID) AS hi
OUTER APPLY
(
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT(hi.FullPath, ehw.EmployeeID, '.')) AS FullPath
FROM EmployeeHierarchyWide AS ehw
WHERE
ehw.ManagerID = hi.EmployeeID
) AS recursive
) AS i
CROSS APPLY
(
SELECT TOP(1)
ho0.*
FROM dbo.hierarchy_outer(@@SPID, i.EmployeeID, i.FullPath) AS ho0
) AS ho
WHERE
i.EmployeeID IS NOT NULL
) AS p
Use of OUTER APPLY between the hierarchy_inner() function and the base table query eliminated the need to play games with the estimates with that function’s output. In experimenting with the hierarchy_outer() function call I discovered that telling the optimizer that it would return only one row eliminated the need to work with the outer estimate in order to remove the Merge Join and Row Count Spool. This was done by using a TOP(1), as is shown in the table expression [ho] in the above query. A similar TOP(1) was used to control the estimate coming off of the hierarchy_anchor() function, which helped the optimizer to eliminate the extra anchor seeks into EmployeeHierarchyWide that earlier versions of the query suffered from.
Use of OUTER APPLY on the recursive part of the query created an interesting twist: nonmatching rows started cycling back in via the hierarchy_outer() call, creating an endless loop—and an endless query. To solve that issue I migrated the NOT NULL check on EmployeeID inside of derived table [p], and converted the outermost APPLY to a CROSS APPLY—which, luckily, did not change the plan shape. (Had it done so, two NOT NULL checks would have been required in this form of the query.)
The end result query plan (note that this used TF 8649):
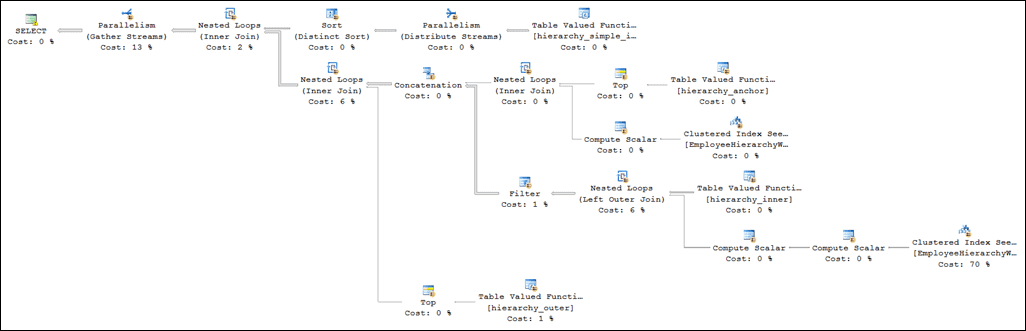
Final Enhancements
The above query returned the correct results, properly supported parallelism, and ran fairly quickly: around 2.2 seconds at DOP 6 on my laptop. However, the work was not completely done.
While attempting to further reduce the run time I began experimenting with different options and ended up playing with a scalar version of the hierarchy_outer() function. Instead of returning a row, it returned 0 when it successfully enqueued a row. If a NULL EmployeeID was passed in it would return NULL, thereby signaling an invalid row. This changed the query to the following form:
SELECT
p.*
FROM
(
SELECT DISTINCT
x
FROM dbo.hierarchy_simple_init(@@SPID)
) AS v
CROSS APPLY
(
SELECT
i.EmployeeID,
i.FullPath
FROM
(
SELECT
anchor.*
FROM
(
SELECT TOP(1)
*
FROM dbo.hierarchy_anchor(v.x, @@SPID) AS ha0
) AS ha
CROSS APPLY
(
SELECT
EmployeeID,
CONVERT(VARCHAR(900), CONCAT('.', EmployeeID, '.')) AS FullPath
FROM EmployeeHierarchyWide
WHERE
ManagerID IS NULL
) AS anchor
UNION ALL
SELECT
recursive.*
FROM dbo.hierarchy_inner(v.x, @@SPID) AS hi
OUTER APPLY
(
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT(hi.FullPath, ehw.EmployeeID, '.')) AS FullPath
FROM EmployeeHierarchyWide AS ehw
WHERE
ehw.ManagerID = hi.EmployeeID
) AS recursive
) AS i
CROSS APPLY
(
VALUES(dbo.hierarchy_outer_scalar(@@SPID, i.EmployeeID, i.FullPath))
) AS ho (value)
WHERE
ho.value IS NOT NULL
) AS p
I didn’t expect much from this and tried it only on a whim—so I was pleasantly surprised when the query finished in only 1.4 seconds, a rather large improvement as compared to the 2.2 second run times I’d been seeing with the prior version.
The reason this is faster? The scalar function interface requires only a single underlying call, whereas the table-valued interface requires at least two, plus CLR object conversion overhead, plus CLR iterator overhead. The query plan below shows that the scalar version removed one of the plan’s subtrees, which probably also contributed a small performance gain.

The next step was to hide (i.e. encapsulate) as much complexity as possible. I realized that the various TOP and DISTINCT clauses, as well as the @@SPID calls, could all be handled in a layer of inline T-SQL table valued functions. I created each of the following:
CREATE FUNCTION dbo.hierarchy_init_t()
RETURNS TABLE
AS
RETURN
(
SELECT DISTINCT
x
FROM dbo.hierarchy_simple_init(@@SPID)
)
GO
CREATE FUNCTION dbo.hierarchy_anchor_t
(
@init_token INT
)
RETURNS TABLE
AS
RETURN
(
SELECT TOP(1)
*
FROM dbo.hierarchy_anchor(@init_token, @@SPID)
)
GO
CREATE FUNCTION dbo.hierarchy_inner_t
(
@init_token INT
)
RETURNS TABLE
AS
RETURN
(
SELECT
*
FROM dbo.hierarchy_inner(@init_token, @@SPID)
)
GO
CREATE FUNCTION dbo.hierarchy_outer_t
(
@EmployeeID INT,
@FullPath NVARCHAR(900)
)
RETURNS TABLE
AS
RETURN
(
SELECT
0 AS value
WHERE
dbo.hierarchy_outer_scalar(@@SPID, @EmployeeID, @FullPath) IS NOT NULL
)
GO
Creating these functions allowed me to create a query that came very close to my original goal, and with the same fast query plan I’d managed to achieve in the prior iteration:
SELECT
p.*
FROM dbo.hierarchy_init_t() AS v
CROSS APPLY
(
SELECT
i.EmployeeID,
i.FullPath
FROM
(
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT('.', ehw.EmployeeID, '.')) AS FullPath
FROM dbo.hierarchy_anchor_t(v.x) AS ha
CROSS JOIN EmployeeHierarchyWide AS ehw
WHERE
ehw.ManagerID IS NULL
UNION ALL
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT(hi.FullPath, ehw.EmployeeID, '.')) AS FullPath
FROM dbo.hierarchy_inner_t(v.x) AS hi
INNER JOIN EmployeeHierarchyWide AS ehw WITH (FORCESEEK) ON
ehw.ManagerID = hi.EmployeeID
) AS i
CROSS APPLY dbo.hierarchy_outer_t(i.EmployeeID, i.FullPath) AS ho
) AS p
The only slight annoyance here was the FORCESEEK hint I was forced to put on the recursive side. Without it, the query optimizer decided to use a Hash Join for that part of the plan, which obviously didn’t fit at all. As compared to many of the games played on the way to this query, I found FORCESEEK to be very minor, so I wasn’t too upset by its being there. Plus I was able to convert the odd-looking OUTER APPLY into an INNER JOIN, so I decided that it was a net win.
The final refactoring step was to rename the functions and their outputs to be more general.
I arrived at the following four T-SQL functions, which are what you will find in the archive attached to this post:
- hierarchy_init() – This is the initializer function, and returns a column called “initialization_token.” It is backed by a CLR function called hierarchy_init_inner().
- hierarchy_anchor(@initialization_token) – The anchor function, this returns a column called “value.” It is backed by hierarchy_anchor_inner().
- hierarchy_recursive(@initialization_token) – The recursive function, this returns two columns, “id” (an integer) and “payload” (nvarchar(4000)). The idea is that most hierarchical navigation will be done using some form of integer parent/child ID scheme. The payload, as a string column, can be packed with anything you’d like to carry along for the ride. This function is backed by hierarchy_recursive_inner().
- hierarchy_enqueue(@id, @payload) – This is the outer function. It returns a column called “value” and is backed by the scalar hierarchy_enqueue_inner().
The final version of the query, which you can replicate using the attached scripts, is as follows. Note that I’ve utilized make_parallel(), rather than TF 8649, in order to guarantee a parallel plan.
SELECT
x.*
FROM dbo.make_parallel()
CROSS APPLY
(
SELECT
p.*
FROM dbo.hierarchy_init() AS hi
CROSS APPLY
(
SELECT
i.EmployeeID,
i.FullPath
FROM
(
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT('.', ehw.EmployeeID, '.')) AS FullPath
FROM dbo.hierarchy_anchor(hi.initialization_token) AS ha
CROSS JOIN EmployeeHierarchyWide AS ehw
WHERE
ehw.ManagerID IS NULL
UNION ALL
SELECT
ehw.EmployeeID,
CONVERT(VARCHAR(900), CONCAT(hr.payload, ehw.EmployeeID, '.')) AS FullPath
FROM dbo.hierarchy_recursive(hi.initialization_token) AS hr
INNER JOIN EmployeeHierarchyWide AS ehw WITH (FORCESEEK) ON
ehw.ManagerID = hr.id
) AS i
CROSS APPLY dbo.hierarchy_enqueue(i.EmployeeID, i.FullPath) AS he
) AS p
) AS x
Final Notes and Script Attachments
As mentioned at the top of this post, this was more of a research project than something intended as a solid and proven solution. The techniques presented here have been heavily tested on my laptop and were briefly tested on one real-world project. In both cases I have been extremely happy with the results and have noticed no issues on recent builds of the functions. That said, multithreaded code is always tricky to absolutely guarantee, and I do not know whether some race condition or bug still exists in my code.
Outside of my code there is also a big issue, and it’s called the query optimizer. While I’ve done everything in my power to control it, use of these components in the real world should only be done by advanced practitioners who are very comfortable reading and manipulating query plans. Divergence from ideal plans may result in wrong results, exceptions, or endless loops.
The archive attached to this post includes create scripts for two hierarchy test tables (I wanted to test behavioral differences between deep and wide hierarchies. It turns out there aren’t really any, but since I already did the work you can try yourself.); the CLR functions in a binary format (the C# code will not be published at this time); the T-SQL outer functions; and the final query.
You are licensed to use the code and binaries in any project internal to your company. You are not allowed to re-distribute the code, binaries, or a reverse-engineered version of either as part of another project without my written consent.
If you do use this code I would love to know how it goes; please drop me a line via e-mail or in the comments here.
Enjoy, thanks for reading, and as always let me know if you have any questions!
Acknowledgement
Huge thanks to Julian Bucknall, who kindly fielded my questions as I was writing my lock-free queue implementation.
Update, 2015-10-04
I found and fixed a minor bug in the assembly. The attachment has been updated with the change.
File Attachment: adam_machanic_re_inventing_recursive_cte.zip

This is pretty nifty. I was working on a problem recently where I had to write a recursive query in which any member could be the root node. It was a bit wobbly, and I (almost) wish I still had it in front of me to revisit with some of this.
You’re doing nasty things here, Adam.
Adam could you add the c# code to your sample source code as well? I am very interested to take a look at how you did all this.
@Erik: Glad you enjoyed it
@mark: Precisely 🙂
@Tim: Apologies, but I am not planning to publish the C# code
Are you looking at this more as an academic exercise or a real solution to hierarchical data? Seems much more difficult to setup and query than a closure table and I’d be surprised if it could compete with it on speed. Most people understand closure tables after a 5 min explanation.
@DGS
“Are you looking at this more as an academic exercise or a real solution to hierarchical data?”
Yes.
“Seems much more difficult to setup and query than a closure table and I’d be surprised if it could compete with it on speed.”
Closure tables can certainly help improve performance for certain types of problems. There are various other problems for which they won’t help at all. And much like any other data model solution, they have various drawbacks.
Like anything else an optimal solution depends upon the specific needs of specific scenarios. I don’t think it makes sense to state that one solution is “easier” or “faster” or “better” without understanding various constraints, including:
– The number of nodes in the hierarchy
– The depth of the hierarchy
– The degree to which the hierarchy can become ragged and/or unbalanced- The change rate–especially with regard to re-parenting
– The importance of history–especially important when reporting off of bitemporal hierarchical models
– The nature of the queries expected in the workload, e.g. navigation by descendent, navigation by ancestor, specific path-based calculation or logic, and so on
Bottom line: If closure tables solve your specific problem for your specific workload, great! If nested sets or some form of a materialized path model works for you, that’s great too.
I am not aware of any general modeling technique that can completely eliminate some form of recursive querying for all classes of problems. And aside from adjacency lists, there is no one modeling technique that supports all classes of hierarchy problems. Let’s not forget that adjacency lists also support more general graph problems, which none of the aforementioned solutions can help with.
With regard to querying adjacency lists, what I’ve detailed here is only one of many potential solutions. As mentioned in the main body of the post, you must pick your favorite poison.
–Adam
Ditto DGS’s question, but for slightly different motivations. I ask because for this specific scenario (hierarchical data), we’ve had the hierarchyid datatype since SQL 2008. With your dataset, I was able to achieve decent speeds for answering questions of the type "who reports to employee x?" and "who does employee x report to?" without having to write (and maintain) a CLR function or "trick" the optimizer into doing the efficient thing.
@Ben:
It sounds like hierarchyId works for you and you’re comfortable with the tradeoffs. In that case switching to something different would be a complete waste of time.
–Adam
@Ben
I’m a bit confused; if hierarchyId is doing the job so well on your end, what are you using recursive CTEs for?
https://twitter.com/spartansql/status/573269014434197504
–Adam
One of the classics…Nice one.
Does the attachment still include the binar(y/ies)? I was going to try it out and only saw sql scripts
@Eric
The binaries are in the scripts.
Hi Adam,
We are using hirerachy ID in our project. We have also used GetAncestor function in the project. We start facing issues when we check-in code to TFS (to the respective sqlproj file) and build the solution. We are thrown the following error:
"An error occurred in the Microsoft .Net Framework while trying to load assembly id 1. The server may be running out of resources, or the assembly may not be trusted with PERMISSION_SET = EXTERNAL_ACCESS or UNSAFE."
We tried changing the permissions of the sqlproj file to EXTERNAL_ACCESS and UNSAFE but to no avail.
Please help.
Thanks!
@shreya
Apologies, but I don’t know much about what might cause that in TFS. I’d recommend posting to the MSDN forums.
–Adam
I most say.. Pretty impressive! But I didn’t get confident with the CLR (.NET implementation), can you go through that code?
@John V
The C# code is not published at this time, so there’s nothing to go through there. You can download the compiled binaries attached to the post, if you like.
Best,
Adam
I wonder if you would have had better luck with the query optimizer if you embedded the C# recursive CTE inside of a T-SQL recursive CTE? The T-SQL recursion would just stop after 1 or 2 levels, with the actual work being done by the C# code and returned as either the initial select or the recursive select. The idea being that if the query optimizer thinks it’s a recursive CTE, and it is, just not in the way it thinks, perhaps it might still lead it making valid plan choices.
@Dennis: unfortunately the implementation of T-SQL recursive CTE is in fact the problem itself. There is no way to both use it and remedy its behavior simultaneously–at least none I can think of. Do you have an actual implementation in mind?
Some questions to ask when working on this problem: How will the data get into the C# if the CTE terminates early? How will it be made to go parallel, ideally in a safe way? And finally, how will the spool be eliminated?
–Adam
I have:
level group parent child
1 a p1 c1
1 a p1 c2
1 a p2 c3
2 a c1 c4
2 a c2 c5
1 b p4 c6
how to I get this:
level group parent child
1 a p1 c1
2 a c1 c4
1 a p1 c2
2 a c2 c5
1 a p2 c3
1 b p4 c6
Comments are closed.